信安类的专业一般接触到的都是 cryptographic hash, 比如 MD5, SHA 系列, SM3。
non-cryptographic hash 指的是未解决原像问题、第二原像(弱碰撞)和强碰撞的 hash 函数。追求效率的应用中通常使用的是 non-cryptographic hash, 因为它们更快。
在 redis, Memcached, Cassandra, HBase, Lucene 都使用了 Murmurhash(一种 non-cryptographic hash)。因此有人说 non-cryptographic hash 才是主流 hash 函数。在只需要判断数据是否发生意外变化(如 CRC), 或是将正常数据在尽可能少的碰撞下分桶时, 这么说可能也没错。
除了 murmurhash, 后来又出现了更快的 xxhash。

每个人在这个社会上生存, 都会有一个属于自己的标记, 用于区分不同的个体。通常使用名字就可以了。但是一个名字也并不能完全表示一个人, 因为重名的人很多。所以我们可以使用一个身份证号或者指纹来表示独一无二的一个人。
同样在互联网的世界, 使用一个符号来表示一个独一无二的事物也很重要。比如我们下载一个文件, 文件的下载过程中会经过很多网络服务器、路由器的中转, 如何保证这个文件下载过程中没有丢包, 被完整的下载下来了呢? 我们不可能去检测这个文件的每个字节, 也不能简单地利用文件名、文件大小这些极容易伪装的信息去判断。这时候, 我们就需要一种指纹一样的标志来检查文件的可靠性, 这种指纹就是我们现在所用的 Hash 算法(也叫散列算法)。
比如从 mysql 官网下载 mysql 时, 在软件包的右下角, 都会有一个 MD5 算法算出来的 hash 值。这个 hash 值有什么用呢? 其实这是给我们校验下载的软件包是否完整用的。当我们下载完成后, 可以通过相关的手段, 比如在 Linux 系统中可以通过 md5sum 这个命令, 计算我们下载的软件包的 hash 值, 然后和官网给出的 hash 值进行比较, 如果两个相等, 就表示文件被完整的下载了。
所谓数据的完整性, 指的是数据在网络传输中是否被篡改、是否丢包, 发送方发出的数据和接收方接收的数据是一样的, 就表明数据是完整的。如何评估数据的完整性? 通常使用 Hash 散列函数。散列函数的主要任务是验证数据的完整性。通过散列函数计算得到的结果叫做散列值, 这个散列值也常常被称为数据的指纹 (Fingerprint)。
概括来说, 哈希 (Hash) 是将目标文本转换成具有相同长度的、不可逆的杂凑字符串(或叫做消息摘要)。
而加密 (Encrypt) 是将目标文本转换成具有不同长度的、可逆的密文。Hash 算法严格上来说并不属于加密算法, 而是与加密算法属于并列关系的一种算法。
有加密就有解密, 而 hash 算法是不可逆, 因此不能算加密算法。这里的不可逆既指不能根据转换后的结果逆转回原文, 也指对于两个输入, 即使其转换结果相同也不能说这两个输入就一定相同。因为, Hash 算法的定义域是一个无限集合, 但是值域确是一个有限集合, 将一个无限集合映射到有限集合上, 每个哈希结果都存在无数个可能的目标文本, 因此哈希是一个多对一的映射, 所以它也不存在逆映射。但是对于加密算法, 它的结果往往取决于输入, 其定义域和值域都是无限集合, 明显是一个一一映射, 对于一一映射, 理论上都是可逆的。
常见的 Hash 算法有: MD5、SHA-1、HMAC、HMAC-MD5、HMAC-SHA1 等
一个优秀的散列算法有几个重要的特征:
在文件传输时, 散列算法就是一种以较短的信息来保证文件唯一性的标志, 这种标志与文件的每一个字节都相关, 而且难以找到逆向规律。因此, 当原有文件发生改变时, 其标志值也会发生改变, 从而告诉文件使用者当前的文件已经不是你所需求的文件。
这种场景, 对 hash 碰撞的要求要低于计算的速度, 因为文件较大时, 计算的速度会更重要。
在密码学中, hash 算法的作用主要是用于消息摘要 (Message Digest), 它主要用于对整个消息的完整性进行校验。举个例子, 我们登陆 B 站的时都需要输入密码, 那么 B 站的数据库会保存明文的密码吗? 如果会明文保存, B 站的 DBA 肯定会看到每个人的密码是什么, 很不安全; 同时如果用户在注册登录时也是明文在网络上传输账号密码, 这个信息也会被人恶意截取, 都会有很多安全问题。
通常一个系统都不会明文存储用户的密码, 一般, 用户在注册的时候, 密码在用户侧还未提交时, 就会使用密码的明文计算一个 hash 值, 然后传输到后端系统, 并将密文记录到数据库中, 用户登录时, 在用户侧在使用相同的算法对密码计算一个 hash 值, 传到后端后, 将这个 hash 值和数据库中的 hash 值进行比较, 如果相同就登录成功; 这样就避免了在网络传输或公司的 DBA 泄露用户密码, 而且密码始终是在用户侧, 所以只要用户知道密码的明文是什么。
在这些应用场景里, 对于抗碰撞和抗篡改能力要求较高, 对速度的要求在其次。一个设计良好的 hash 算法, 其抗碰撞能力是很高的。以 MD5 为例, 其输出长度为 128 位, 碰撞的概率是 2 的 128 次方分之一
在用到 hash 进行管理的数据结构中, 就对速度比较重视, 对抗碰撞不太看中, 只要保证 hash 均匀分布就可以。比如 Hashmap, hash 值 (key) 存在的目的是加速键值对的查找, key 的作用是为了将元素适当地放在各个桶里, 对于抗碰撞的要求没有那么高。换句话说, hash 出来的 key, 只要保证 value 大致均匀的放在不同的桶里就可以了。但整个算法的 set 性能, 直接与 hash 值产生的速度有关, 所以这时候的 hash 值的产生速度就尤为重要。
很简洁的一个乘加迭代运算, 在不少的 hash 算法中, 使用的是异或;加法进行迭代。
Message Digest Algorithm MD5(消息摘要算法 5) 为计算机安全领域广泛使用的一种散列函数, 用以提供消息的完整性保护。是计算机广泛使用的杂凑算法之一, 将数据(如汉字)运算为另一固定长度值, 是杂凑算法的基础原理, MD5 的前身有 MD2、MD3 和 MD4。
MD5 算法具有以下特点:
MD5 应用场景:
安全哈希算法 (Secure Hash Algorithm) 主要适用于数字签名标准里面定义的数字签名算法 (Digital Signature Algorithm DSA)。对于长度小于 2^64 位的消息, SHA1 会产生一个 160 位的消息摘要。当接收到消息的时候, 这个消息摘要可以用来验证数据的完整性。在传输的过程中, 数据很可能会发生变化, 那么这时候就会产生不同的消息摘要。
SHA1 算法原理:
首先进行 SHA1 分组: 对于任意长度的明文, SHA1 可以产生 160 位的摘要。对明文的分组处理过程如下:
分组之后, 对所得到的若干分组反复重复处理。对每个明文分组的摘要生成过程如下:
SHA1 有如下特性:
MurmurHash 是一种非加密型哈希函数, 适用于一般的哈希检索操作。 由 Austin Appleby 在 2008 年发明, 并出现了多个变种, 都已经发布到了公有领域。与其它流行的哈希函数相比, 对于规律性较强的 key, MurmurHash 的随机分布特征表现更良好。其在 Redis, Memcached, Cassandra, HBase, Lucene 都使用了这种 hash 算法。所有很有必要说一下。
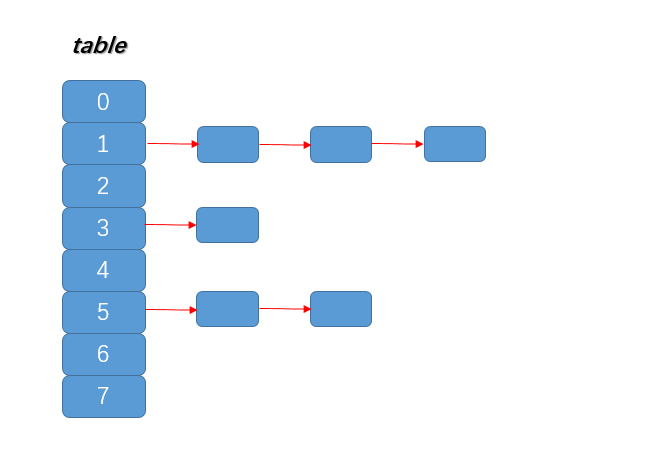
Redis 在实现字典时用到了两种不同的哈希算法, MurmurHash 便是其中一种(另一种是 djb)。MurmurHash 在 Redis 中应用十分广泛, 包括数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。发明算法的作者被邀到 Google 工作, 该算法最新版本是 MurmurHash3, 基于 MurmurHash2 改进了一些小瑕疵, 使得速度更快, 实现了 32 位(低延时)、128 位 HashKey, 尤其对大块的数据, 具有较高的平衡性与低碰撞率。
与 MD5 这些讲究安全性的摘要算法比, MurmurHash 并不关注安全性, 比如在 Redis 内部只是为主键做个 Hash 而已, 就不需要安全性了。因此 MurmurHash 是一种 non-cryptographic 的 hash 算法, 比安全散列算法快几十倍。
在 Java 中, 有很多地方都使用了 MurmurHash, 比如 Guava 包、Jedis 包, Cassandra 包中都有这种 hash 算法。
MurmurHash 算法总结: 高运算性能, 低碰撞率。
这里运行了 100000 次, 但是 Set 中去重后只有 99998 个元素, 可以使用 Hashing.murmur3_32(seed) 的 seed 降低元素的重复。
MurmurHash 的应用除了上面说的 redis, 在很多时候都可以应用到, 比如短连接服务生成短连接、BloomFilter 都可以使用。
MD5、SHA1 等 hash 算法作为一种不可逆算法, 一定程度上保证了密码的安全性, 但是 MD5 等 hash 算法真的是完全安全的吗, 其实不然。
从概率来说, 2 的 128 次方遍历后至少出现两个相同的 MD5 值, 但是 2 的 128 次方有多大? 3402823669209384634633746074317.7 亿, 就算全世界最快的超级计算机也要跑几十亿年才能跑完。可是, 王小云院士破解了 MD5。这里所说的破解, 并不是给王小云院士一个 MD5 散列值, 然后她就能通过计算还原出原文来。从密文推算出明文理论上是不可能的, 所以王小云的研究成果不能通过 MD5 的散列值逆向推算出明文。王小云的研究成果是给定消息 M1, 能够计算获取 M2, 使得 M2 产生的散列值与 M1 产生的散列值相同。这样, MD5 的抗碰撞性就不满足了, 使得 MD5 不再是安全的散列算法。从而导致 MD5 用于数字签名将存在严重问题, 因为可以篡改原始消息, 而生成相同的 Hash 值。因此, 业界专家普林斯顿计算机教授 Edward Felten 等强烈呼吁信息体系的设计者赶快更换签名算法, 而且他们侧重这是一个需要当即处理的问题。
同时美国国家技能与规范局 (NIST) 于 2004 年 8 月 24 日宣布专门谈论, 谈论的首要内容为: “在近来的世界暗码学会议 (Crypto 2004) 上, 研究人员宣布他们发现了破解数种 HASH 算法的办法, 其间包含 MD4, MD5, HAVAL-128, RIPEMD 还有 SHA-0。剖析标明, 于 1994 年代替 SHA-0 成为联邦信息处理规范的 SHA-1 的削弱条件的变种算法能够被破解; 但完好的 SHA-1 并没有被破解, 也没有找到 SHA-1 的碰撞。研究结果阐明 SHA-1 的安全性暂时没有问题, 但随着技能的发展, 技能与规范局计划在 2010 年之前逐步筛选 SHA-1, 换用别的更长更安全的算法(如 SHA-224、SHA-256、SHA-384 和 SHA-512) 来代替。”
所以从这里也可以看出, 单步的 hash 算法还是存在很大的漏洞, 容易被碰撞。那么该如何进一步的加强 hash 算法的安全性呢, 可以使用如下的办法:
salt 可以简单的理解成: 随机产生的一定长度的, 可以和密码相结合, 从而使 hash 算法产生不同结果的字符串。也就相当于你的新密码 = 旧密码 ; 随机的盐值, 然后对新密码进行 hash。 优点: 这种方法会极大防止受到彩虹表的攻击, 因为即便攻击者构造出彩虹表, 因为你使用了 hash(密码; salt), 攻击者彩虹表里的哈希值 hash(密码)和你数据库中的哈希值是不同的。
通过迭代计算的方式增加计算密码的成本。迭代的周期控制在用户可以接受范围内, 这样攻击者的计算和时间成本就会大大增加。
一般到此时, hash 结果就比较安全了。但是如果还需要更加地安全, 可以继续对这种方法计算出来的 hash 值使用加密算法加密。