线上的Redis服务被用来当做缓存用,缓存有一个缺点,就是一旦断电,缓存中的数据将全部丢失。通常情况下,缓存中的数据是允许丢失的,但是有些业务场景下,无法容忍数据丢失,这个时候,就需要我们将缓存中的内容保存起来,或者说不保存,但是你能够把它“恢复出来”。
既然要恢复数据,那我们可以从数据库中,例如mysql中,将所有的数据重新读入Redis中即可,这个方法本身是可行的,但是有2个缺点,其一是会对数据库产生不必要的读取压力,其二是从数据库中"植入"到缓存中的过程,可能会比较长,这个过程中,应用程序需要容忍响应慢的问题。
看来直接恢复,有些难度,Redis中索性将这些缓存中的数据,通过2种机制保存起来,"持久化"到磁盘中,这样下次恢复数据的时候,就会比较快。这2种机制,分别是AOF和RDB,今天来看AOF机制。
1、AOF的内容是什么?
AOF全称是Append Only File,它类似MySQL中的binlog,将MySQL中执行过的命令保存起来,等到我们想要恢复数据的时候,再从AOF日志中将这些命令重新写入到Redis实例中即可。AOF文件中保存的是在Redis中执行过的命令。假设我们执行一个hello world的命令,如下:
127.0.0.1:6380> set hello world OK
它对应的AOF文件内容就是:
*2 # *2代表下面的命令有2个关键字:分别是"select" 和数字0 $6 # $6表示select关键字含有6个字符,也就是6个字母; SELECT # SELECT就是系统帮我们补充的关键字 $1 # $1表示数字0含有1个字符 0 # 数字0 *3 # -----这里开始第二个命令---*3表示这个命令有3个关键字,分别是set、hello、world $3 # $3表示set含有3个字符,也就是3个字母; set # set就是我们输入的关键字 $5 # $5表示接下来的关键字hello含有5个字符 hello # hello就是我们输入的关键字 $5 # $5表示接下来的关键字world含有5个字符 world # hello就是我们输入的关键字
总体上说,这个set hello world的命令的AOF文件,包含2个部分:第一部分是系统补充的select 0,表示选定数据库编号0,Redis默认有16个db编号,分别是0~15,如下:
127.0.0.1:6380> select 0 OK 127.0.0.1:6380> select 15 OK 127.0.0.1:6380[15]> select 16 (error) ERR invalid DB index
第二部分是我们手工执行的set hello world命令。
再补充一点,AOF文件中每行输出之间的换行符是 。
到这里,我们了解了AOF文件中的内容。
2、AOF什么时候写磁盘 ?
我们知道MySQL使用基于WAL(write ahead log)技术的两阶段提交模式来保证数据的可靠性,也就是先写redo log ,再写binlog,再标记redo log为commit的方法来确保数据的可靠性。Redis中,正好相反,它采用的是先写数据库,再写AOF的方法来保证数据的可靠性。
Redis中写内存和写AOF日志的示意图如下:

从上面的示意图不难看出来,AOF是先写内存,再写磁盘的。
这么设计,有什么利弊?
利:
先写内存,再写磁盘,先让Redis服务执行命令,只有命令能执行成功,才会被记录到日志中,否则,系统就会直接向客户端报错。所以,这种方式可以避免出现记录错误命令的情况。在命令执行后,才写日志,也就意味着不会阻塞当前命令弊:
如果针对某条命令,数据库内存写完之后,还没来的及写磁盘日志,数据库就宕机了,那么这条日志没有记录到AOF中,再次利用AOF恢复的时候,不就丢数据了么?确实存在这种风险AOF虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。针对风险一,Redis可以通过配置策略来将这种风险控制到最小。下面我们就来看AOF日志文件写入到磁盘的一些细节。
当客户端执行了写入命令后,写入的内容会进入到AOF的buffer中,执行完一条命令之后,Redis会调用刷盘函数flushAppendOnlyFile来进行刷盘,而这个函数中配置了一个刷盘的策略,这个策略由Redis的参数appendfsync来确定,如下:
127.0.0.1:6380[15]> config get appendfsync 1) "appendfsync" 2) "everysec"
这个参数可以配置为以下几个值:
always:Redis在每个事件循环的时候都要将aof_buffer中的内容写入aof文件,并且同步到磁盘中
everysec:Redis在每个事件循环的时候都将aof_buffer中的数据写入到aof文件,并且每1s要在子线程中对aof文件进行一次同步,它也是Redis的默认值。
no:Redis在每个事件循环的时候都将aof_buffer中的数据写入到aof文件,由操作系统控制何时对aof文件进行一次同步
其中,no值模式下,aof文件写入的速度是最快的,因为不会每个事件都强制刷盘,而always值模式下,aof文件写入的效率是最慢的,因为每个事件都要刷盘,会影响Redis的性能,但是提高了安全性。总之:
安全性考虑:always > everysec > no
持久化效率:always < everysec < no
1、为什么要重写?
随着命令不断写入AOF文件,该文件会越来越大,AOF的重写机制就是为了解决这个问题的。
重写后AOF文件,将会变小,之所以重写后文件变小,有以下几个原因:
1)进程内已经超时的数据不再写入文件
2)旧的AOF文件中含有无效指令,例如set key,del key这样的对称命令,会相互抵消,最终减少文件的大小。
3)多条写命令可以合并为一个,例如lpush list a,lpush list b......可以合并为lpush list a b,在这个过程中,为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型操作,以64个元素为界限拆分为多条。
如下图,重写前AOF中包含5个命令,重写后,仅包含1个命令:
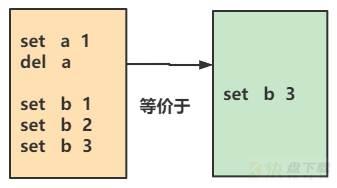
AOF重写机制降低了文件占用的空间,而且使得下次加载AOF文件的速度变快。
2、AOF重写触发方法
可以手动触发和自动触发。
(1)、手动触发过程如下:
[root@VM_48_10_centos ~]# redis-cli 127.0.0.1:6379> bgrewriteaof Background append only file rewriting started 127.0.0.1:6379>
自动触发:
根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数来确定自动触发重写的时机。
auto-aof-rewrite-min-size参数:表示运行AOF重写时文件最小体积,默认为64MB,以下简称AS参数
auto-aof-rewrite-percentage:表示当前AOF文件和上一次重写后AOF文件的比值。以下简称AP参数
(2)、自动触发AOF重写需要满足如下条件:
aof_current_size>AS
&&
(aof_current_size-aof_base_size)/aof_base_size >= AP
其中,aof_current_size和aof_base_size可以使用info Persistence统计信息中查看。如下:
[root@VM_48_10_centos ~]# redis-cli 127.0.0.1:6379> info Persistence # Persistence loading:0 aof_enabled:1 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok aof_current_size:599 aof_base_size:599 aof_pending_rewrite:0 aof_buffer_length:0 aof_rewrite_buffer_length:0 aof_pending_bio_fsync:0 aof_delayed_fsync:0
3、AOF重写过程
当redis自动触发AOF重写时,redis内部的执行流程图如下:

流程说明:
1)开始执行AOF重写请求,如果当前正在执行bgsave保存RDB文件操作,则重写命令会延迟到basave完成之后再执行。
2)父进程执行fork创建子进程,开销等同于bgsave过程
3.1)主进程fork完操作之后,继续响应其他命令,所有修改命令依然写入AOF缓冲区并根据appendfsync策略同步到磁盘,保证原有AOF机制正确
3.2)由于fork操作运用写时复制(Copy-On-Write)技术,子进程只能共享fork操作时的内存数据,此时父进程仍然还在响应命令,redis使用"AOF重写缓冲区"保存这部分新数据,防止新AOF文件生成期间丢失这部分数据。可以通俗的理解生成新AOF文件的过程中产生的增量数据,保存在aof_rewrite_buf里面
4)子进程根据内存快照,按照命令合并规则写入到新的AOF文件,每次批量写入硬盘,默认为32MB写一次,由参数aof-rewrite-incremental-fsync控制,防止单次刷盘过多造成硬盘阻塞。
5.1)新AOF写入完成后,子进程发送信号给父进程,父进程更新统计信息
5.2)父进程把AOF重写缓冲区的数据写入到新的AOF文件
5.3)使用新的AOF文件替换老文件,完成AOF重写。
为了更好理解,再补充一个示意图:

4、补充说明
上述AOF重写操作,有几个需要注意的点需要说明:
1、AOF重写缓冲区,是父进程中的一块重写缓冲;
2、AOF重写缓冲区中的数据写入到新的AOF是由父进程控制的
3、内存数据的拷贝是基于“写时复制“技术的,不会拷贝Redis当前的所有内存,只是会拷贝内存页表
4、fork的瞬间会对主进程造成一定的阻塞,Redis中保存的数据量越多,内存页表越大,fork的阻塞情况越明显
写时复制(Copy-On-Write,COW)说明
这里再重点说下fork操作,fork操作的过程如下:
一开始,fork拷贝内存页表后,父进程和子进程只想相同的内存区域

随着业务对已经存在的数据的修改,父子进程指向的内存开始逐渐分离,(因为子进程要保存旧的数据):

最后,父子进程指向完全不同的区域。
我们使用Redis源码来进行分析,先来看优化前的版本:

1、父进程触发重写
2、父进程调用rewriteAppendOnlyFileBackground函数,fork出来一个子进程
3、真正的fork过程,调用系统fork()函数
4、这个阶段,父进程和子进程都有相关动作。父进程是判断当前是否有子进程,为下一步做准备;而子进程开始调用rewriteAppendOnlyFile函数,生成一个tmp-aof的新文件
5、这个阶段,父进程和子进程都有相关动作。父进程将业务写入利用aofRewriteBufferAppend函数写入到AOF重写缓冲区中;子进程调用rewriteAppendOnlyFIleRio遍历redis把所有key-value以命令的方式写入新aof文件
6、子进程写入新的AOF文件完成后,调用exitFromChild退出重写
7、父进程调用backgroundRewriteDoneHandler函数进行后续处理
8、父进程调用aofRewriteBufferWrite函数将AOF缓冲区中积攒的写命令缓存写入子进程创建的tmp-aof文件
9、完成tmp-aof和旧的AOF文件的Rename操作。
在上述AOF重写的过程中,存在一个风险点:如果AOF重写过程中,父进程写入的数据量过大,当AOF重写完毕后,新老文件交替,需要父进程将AOF重写buffer里面的数据,写入到新的AOF文件中,这个过程中,可能需要很长时间,那么父进程就有阻塞的风险。
为了解决这个问题,Redis在新版本中,引入了Pipe优化,也就是引入管道来优化:

重点观察红色部分:
1、fork子进程之前,先调用一个aofCreatePipes命令创建一个管道,代码中也可以看到:
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
long long start;
if (server.aof_child_pid != -1) return REDIS_ERR;
if (aofCreatePipes() != REDIS_OK) return REDIS_ERR;
start = ustime();
if ((childpid = fork()) == 0) {
char tmpfile[256];
函数的第6行创建了管道,第8行才是真正的fork语句。
2、父进程在图中步骤5之后,通过函数aofChildWriteDiffData来向管道写入数据,
/* Event handler used to send data to the child process doing the AOF
* rewrite. We send pieces of our AOF differences buffer so that the final
* write when the child finishes the rewrite will be small. */
//事件处理句柄,用来发送数据给子进程处理aof重写操作,发送aof buffer的差异,为了最后让aof buffer写的更少
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
}
这里可以看到,在AOF重写的时候,会将AOF重写buffer中的差异通过管道传输给子进程,让子进程实时应用,从而让最后一步的重写buffer内容变少。
此时子进程通过函数aofReadDiffFromParent来从管道读取数据,并缓存下来
/* This function is called by the child rewriting the AOF file to read
* the difference accumulated from the parent into a buffer, that is
* concatenated at the end of the rewrite. */
ssize_t aofReadDiffFromParent(void) {
}
3、再往后看,当子进程生成新aof文件后,它会通过另外一个控制管道向父进程发送”!”,发起停止数据传输请求,也就是第一个write '!'
4、父进程收到停止信号后调用函数aofChildPipeReadable函数,
设置server.aof_stop_sending_diff=1停止数据传输,并向子进程回复”!”,表示同意停止,也就是第二个write '!'
/* This event handler is called when the AOF rewriting child sends us a
* single '!' char to signal we should stop sending buffer diffs. The
* parent sends a '!' as well to acknowledge. */
void aofChildPipeReadable(aeEventLoop *el, int fd, void *privdata, int mask) {
}
5、子进程收到父进程的应答,调用rioWrite()把之前通过管道积攒的数据追加到新的aof文件,最后退出。
注意,这里就是核心优化:子进程来处理大部分AOF重写期间的差异数据,而不是用父进程,避免父进程阻塞
6、由于子进程和父进程之间不可能实现实时同步,一定存在一部分数据差,在子进程写入差异数据期间,父进程又产生了差异数据,所以,当子进程退出后,父进程还是需要调用aofRewriteBufferWrite函数将AOF缓冲区中积攒的写命令缓存写入子进程创建的tmp-aof文件
7、其他过程,就和优化前一样了。
在这个管道优化过程中,一共引入了三个管:
父子进程数据传输管道;子进程向父进程发送控制命令write '!'的控制管道父进程向子进程回复控制命令write '!'的控制管道接下来,我们使用AOF重写过程中的日志,来进行分析aof rewrite buffer的大小变化:
24:M 02 Nov 17:20:30.260 * Starting automatic rewriting of AOF on 400% growth 24:M 02 Nov 17:20:31.631 * Background append only file rewriting started by pid 97 24:M 02 Nov 17:21:58.535 * Background AOF buffer size: 73 MB 24:M 02 Nov 17:22:29.727 * Background AOF buffer size: 174 MB 24:M 02 Nov 17:22:30.975 * Background AOF buffer size: 180 MB 24:M 02 Nov 17:22:54.425 * Background AOF buffer size: 271 MB 24:M 02 Nov 17:22:55.726 * Background AOF buffer size: 277 MB ----------- 24:M 02 Nov 18:36:41.436 * Background AOF buffer size: 11870 MB 24:M 02 Nov 18:40:12.701 * Background AOF buffer size: 11873 MB 24:M 02 Nov 18:40:16.931 * Background AOF buffer size: 11879 MB 24:M 02 Nov 18:40:59.444 * Background AOF buffer size: 11879 MB 24:M 02 Nov 18:41:16.422 * Background AOF buffer size: 11878 MB 24:M 02 Nov 18:41:30.737 * Background AOF buffer size: 11875 MB 24:M 02 Nov 18:41:44.891 * Background AOF buffer size: 11873 MB 24:M 02 Nov 18:50:22.751 * Background AOF buffer size: 11779 MB ---------- 24:M 02 Nov 21:32:14.358 * Background AOF buffer size: 675 MB 24:M 02 Nov 21:33:45.722 * Background AOF buffer size: 471 MB 24:M 02 Nov 21:35:41.267 * Background AOF buffer size: 277 MB 24:M 02 Nov 21:36:45.015 * Background AOF buffer size: 177 MB 24:M 02 Nov 21:38:01.697 * Background AOF buffer size: 75 MB 24:M 02 Nov 21:38:01.697 * Background AOF buffer size: 75 MB 24:M 02 Nov 21:44:26.592 * AOF rewrite child asks to stop sending diffs. 97:C 02 Nov 21:44:26.592 * Parent agreed to stop sending diffs. Finalizing AOF... 97:C 02 Nov 21:44:26.592 * Concatenating 2410.24 MB of AOF diff received from parent. 97:C 02 Nov 21:44:37.168 * SYNC append only file rewrite performed 97:C 02 Nov 21:44:37.722 * AOF rewrite: 13945 MB of memory used by copy-on-write 24:M 02 Nov 21:44:40.589 * Background AOF rewrite terminated with success 24:M 02 Nov 21:44:40.600 * Residual parent diff successfully flushed to the rewritten AOF (9.90 MB) 24:M 02 Nov 21:44:40.602 * Background AOF rewrite finished successfully
从日志中,可以看到,这个AOF Rewrite Buffer的大小,有一个先升后降的过程,结合上面的示意图,我们来分析原因。
首先,来看这个AOF Buffer的生成:
/* This function free the old AOF rewrite buffer if needed, and initialize
* a fresh new one. It tests for server.aof_rewrite_buf_blocks equal to NULL
* so can be used for the first initialization as well. */
//它会尝试将aof_rewrite_buf_blocks设置为NULL,初始化
void aofRewriteBufferReset(void) {
if (server.aof_rewrite_buf_blocks)
listRelease(server.aof_rewrite_buf_blocks); // 将所有的blocks全部free掉
server.aof_rewrite_buf_blocks = listCreate();
listSetFreeMethod(server.aof_rewrite_buf_blocks,zfree);
}
可以发现,函数aofRewriteBufferReset函数中,利用listCreate函数创建了一个server.aof_rewrite_buf_blocks的list列表
再来看AOF Buffer的累积增加,从函数名称判断,一定是aofRewriteBufferAppend这个函数来实现的,是通过append的方法来在rewrite buffer的末尾加入字节,现在我们去代码中分析这个逻辑:
/* Append data to the AOF rewrite buffer, allocating new blocks if needed. */
// 将数据加载到AOF BUFFER中,必要时候,会分配新的数据块
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
listnode *ln = listLast(server.aof_rewrite_buf_blocks);
aofrwblock *block = ln ? ln->value : NULL;
while(len) {
/* If we already got at least an allocated block, try appending
* at least some piece into it. */
if (block) {
unsigned long thislen = (block->free < len) ? block->free : len;
if (thislen) { /* The current block is not already full. */
memcpy(block->buf+block->used, s, thislen);
block->used += thislen;
block->free -= thislen;
s += thislen;
len -= thislen;
}
}
上述代码第4行写了ln是aof rewrite buffer的末尾位置,第7行的参数len是我们要写入的字节数,后续逻辑是在当前block中分配需要的字节数,如果不够,则转入下一个block进行分配。
除了增加,还有一个后续减少的过程,我们来看AOF Rewrite Buffer减小是在哪个部分,唯一的可能就是在管道发送给子进程之后,对响应的aof rewrite buffer进行缩小,那么这块儿逻辑只能在aofChildWriteDiffData函数中:
/* Event handler used to send data to the child process doing the AOF
* rewrite. We send pieces of our AOF differences buffer so that the final
* write when the child finishes the rewrite will be small. */
//事件处理句柄,用来发送数据给子进程处理aof重写操作,发送aof buffer的差异,为了最后让aof buffer写的更少
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
REDIS_NOTUSED(el);
REDIS_NOTUSED(fd);
REDIS_NOTUSED(privdata);
REDIS_NOTUSED(mask);
while(1) {
ln = listFirst(server.aof_rewrite_buf_blocks); //一个listNode,链表
block = ln ? ln->value : NULL; // 如果表达式一成立,则执行表达式二,否则执行表达式三,如果ln存在是表达式一
if (server.aof_stop_sending_diff || !block) {
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,
AE_WRITABLE);
return;
}
if (block->used > 0) {
nwritten = write(server.aof_pipe_write_data_to_child,
block->buf,block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten); // 从str2往str1复制n个字符
block->used -= nwritten;
}
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}
可以看到,第15行利用block来表示这个aof rewrite buffer的大小,第23~27行,当我们写入n个字节之后,会将aof rewrite buffer使用memmove函数进行一个字节拷贝,拷贝的目的是减小当前这个block,也就是减小aof rewrite buffer,这里,就能够解释过去了。
还有一些技术细节,下次有精力再分享吧。今天文章就到这里,希望通过这篇文章,能够提升大家对AOF重写过程的理解吧。
















